Pretraining is all you need
This post will discuss how the effectiveness of multiple regularization methods and techniques to handle noise was questioned when finetuning a Pretrained Language Model.
Finetuning a pretrained language model is the way to go when tackling most if not all NLP tasks. After a model is pretrained, it can be adapted for multiple tasks by adding a few task-dependent layers and training for a few iterations. Fine-tuned models usually show interesting generalization abilities and stability over models trained from scratch. These qualities have closed the gap between finetuning a PLM model directly and using regularization or noise-handling techniques. In this blog, we will discuss some of these techniques and the papers that questioned their effectiveness.
Noise handling and Early stopping
Paper: Memorisation versus Generalisation in Pre-trained Language Models
This paper studies BERT’s generalization under Label noise. A model generalizes by learning general-purpose patterns while ignoring noise and features that are irrelevant to the task. The noise in this case is introduced by randomly permuting some labels in the training set (injected noise). Authors create datasets with different noise levels by varying the percentage of permuted labels. The generalization of the model is judged based on its performance on the original test set.
During training, a model usually goes through two phases of learning, which are called fitting and memorization by the authors. Fitting is where the model is learning patterns that are useful for the task, this phase is characterized by an increase in the training and validation performance. In the second phase, the model starts memorizing noise and over-fitting. During this phase, the training performance keeps improving while the validation performance is degrading. The authors identified another phase of learning for BERT called settling. It comes after fitting and is characterized by a stable performance on both validation and training sets. This shows BERT’s resilience to memorizing noise. Even in noisy datasets, BERT achieves and keeps an optimal performance for a few epochs before starting to memorize the noise in the third phase.
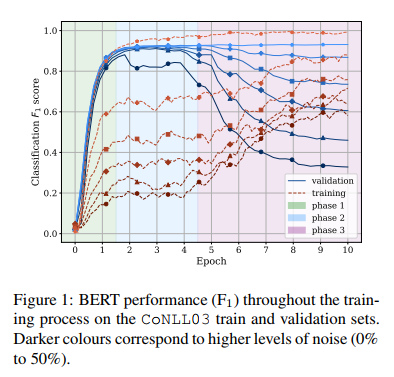
The authors based on these observations argue that when finetuning BERT, one can simply finetune for a fixed number of epochs and does not need to use early stopping, especially in clean datasets where BERT maintains its performance regardless of the number of epochs. Even in the presence of noise, BERT is able to reach comparable performance to training on a clean dataset. But high levels of noise still have the effect of shortening the settling phase duration, which means we need to be careful to stop the training before reaching the memorization phase and starting to over-fit the data. The authors attribute BERT’s robustness to pretraining, after finding that a non-pretrained model does not exhibit a second phase of learning.
Along with the effect of injected noise, Zhu et al., 2022 study also the effect of weak supervision noise. Weak supervision is a technique for quickly annotating datasets by combining heuristic rules and patterns. For example for a Sentiment Analysis task, one can label any text that contains the word “good” as positive. The noise that results from weak supervision can be different from injected noise. Zhu et al., 2022 validate the finding that BERT is robust to injected noise, but found that this does not extend to weak supervision noise, where BERT’s performance can drop drastically at a high noise level. They also experimented with multiple noise-handling methods and found that they have little impact on BERT’s performance even at high levels of noise.
In short, pretraining improves BERT’s generalization to the point where using noise handling has little impact on the performance. The generalization of BERT is obvious under injected noise, but weak supervision noise can fool the model as it can be feature dependent (Zhu et al., 2022).
Label Regularization
paper: Towards Understanding Label Regularization for Fine-tuning Pre-trained Language Models
This paper is motivated by the work in Computer Vision where it was shown that Label Smoothing techniques achieve comparable results to Knowledge Distillation (KD) (Yuan et. al, 2020). The authors provide a comparison of KD and other teacher-free regularization techniques (TF) in the context of Natural Language Understanding (NLU). Different from the work in Yuan et. al, 2020, the student, in this case, is a pretrained language model, and the regularization is applied when finetuning on a downstream NLU task. What was found in this setting is that additionally to the observation that KD and TF deliver comparable results, both techniques deliver negligible improvements over direct finetuning. The authors perform different experiments to finally show that this is due to pretraining.
The label regularization techniques investigated in the paper are Vanilla KD, Label Smoothing (LS), TF-reg, and Self distillation (Self KD). Each of these techniques can be expressed as a function that takes the hard labels and returns a smoothed version (Yuan et. al, 2020).
Vanilla KD
In Vanilla KD (Hinton et al., 2015), we transfer a teacher’s knowledge to a student by minimizing the difference between their outputs. In the equation below, $H(q, p)$ is the cross-entropy loss, while $D_{KL}(p_τ^t, p_τ)$ is the KL divergence between a softened version of the teacher’s and student’s predictions. $p_τ(k)=softmax(z_k/τ)$ is the probability of label $k$, where $z_k$ is the output logit of the model, and $τ$ is the temperature by which the predictions are softened. $\alpha$ is a hyperparameter to control how much attention we pay to the cross entropy loss (hard labels) and the KL divergence loss (teacher’s output).
When $τ=1$, KD equation can be written such that the hard label $q(x)$ is smoothed by the teacher’s output $p^t$ to produce $q’(x)$:
Label Smoothing (LS)
In label smoothing (Szegedy et al., 2015), the output labels are modified and smoothed with a uniform distribution $u(k)=1/K$ where $K$ is the number of classes. You can see the similarity between this equation and the one for KD, where the model’s output is replaced by a fixed distribution. This has a regularization effect by reducing a model’s certainty in its predictions.
TF-reg
Teacher-free KD by manually-designed regularization (TF-reg) (Yuan et al., 2020) is similar to LS but in this case, we mimic the output distribution of a trained teacher. The teacher’s output $p^t$ is replaced with a fixed distribution $p^d$ defined as follows:
$a$ is the probability given to the correct class $c$, it is usually set higher or equal to $0.9$. This means that the correct class will always have a higher probability than the incorrect classes. TF-Reg can be thought of as a manually designed teacher with 100% accuracy (Yuan et al., 2020).
Self distillation
Self-distillation (Yuan et al., 2020) is the same as KD, but this time instead of using a larger model as a teacher, we use a trained copy of the student. In this case, one copy of the student is created and finetuned, then we freeze it and use its output $p_τ^t$ to teach the student.
The authors experimented with finetuning models from scratch. And they found that label regularization significantly improves the results. They also perform a statistical test on whether there is a difference between training with and without label regularization when the model is pretrained and not pretrained. The result was that there is no statistical difference in the case of pretraining, while the difference is statistically significant when the model is trained from scratch.
The paper doesn’t exclude that label regularization can be effective during pretraining. And also the fact that other complex KD techniques might increase the gap during finetuning.
Data Augmentation
paper: How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers?
In this paper, the authors look into the question of how effective is data augmentation when the model is pretrained. They specifically look into task-agnostic data augmentation techniques that can be applied to any task, and what they found is that these techniques fail to provide consistent improvements over directly finetuning a pretrained Language model (BERT, RoBERTa, and XLNet). The authors experiment with two data augmentation techniques: Back Translation (BT) and Easy Data augmentation (EDA).
Back Translation (BT): Data is augmented by translating sequences to another language, and then back again. In this case, they translate English sentences to Germain and then translate each sentence back to six candidate English sentences (using 2 Machine Translation models for English-to-Germain and Germain-to-English). They select the most distant sentence based on word edit distance between the candidates and the original sentence, in order to diversify the generated paraphrases.
Easy Data Augmentation (EDA): Consists of 4 simple text editing operations: synonym replacement, random swap, random insertion, and random deletion. For each sentence, one operation is chosen randomly and applied. EDA was shown to improve the text classification performance of LSTM and CNN models (Wei and Zou, 2019).
Authors study finetuning with and without DA on 6 text classification datasets. Results are provided for 5 training set sizes (500, 1000, 2000, 3000, and Full) that they created out of each training set. LSTM and CNN results are from Wei and Zou, 2019 and only show improvement for EDA.
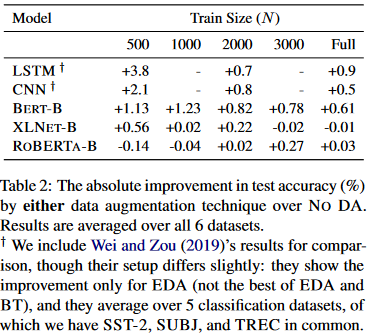
The table shows that DA improves the results of non-pretrained models (CNN and LSTM). While for pretrained models improvements are only apparent for BERT, especially when the size of the training set is ≤ 1000. We would expect DA to improve results at least in low data sizes, but for RoBERTa and XLNet there is no clear difference.
The authors explain the ineffectiveness of DA for RoBERTa and XLNet by their scale of pretraining. They are both pretrained on more data and for longer steps compared to BERT. Based on this, they hypothesize that pretraining brings the same benefits of common DA techniques. Both methods expose the model to linguistic patterns and words that are not seen in the training set, which improves the model’s generalization.
This paper can be viewed as a motivation for more complex and task-specific data augmentations. The authors also mention that task-agnostic data augmentation might still be helpful for out-of-domain generalization when the task data domain was not covered during pretraining. I think even in this case something like domain finetuning will alleviate the need for DA.
Conclusion
Pretraining improves the generalization and robustness of transformer-based models. Techniques for regularizing a model and handling noise were shown to deliver sparse improvements when fine-tuning a pretrained model. This can be viewed as a motivation for using and researching complex techniques to provide benefits that are not covered by the pretraining.